

INTRODUCTION
Arabic is a rich language with a wide collection of dialects in addition to Modern Standard Arabic (MSA). Many of these dialects remain under-studied, primarily due to limited resources (research funding, datasets, etc.). The goal of the Nuanced Arabic Dialect Identification (NADI) shared task series is to alleviate this bottleneck by providing datasets and modeling opportunities for participants to carry out dialect identification, and in general dialect processing. Dialect identification (Abdul-Mageed et al., 2018; Abdul-Mageed et al., 2020a) is the task of automatically detecting the source variety of a given text or speech segment. This year, we design it as a multilabel classification task, in which the given text can belong to more than a single Arabic dialect. It is generally acknowledged across the Arabic NLP community that the Arabic dialects are not mutually exclusive, as they can share lexical terms and expressions, especially for the dialects spoken in geographically proximate areas. Keleg et al. (2023a) analyzed the errors of a single-label dialect classification system, and found that about 66% of these errors are not true errors. Therefore, we use a multilabel classification setup to alleviate such limitation, in an attempt for having a better evaluation of Arabic Dialect Identification systems.
Moreover, we introduce a new subtask for estimating the level of dialectness of text, on a scale between 0 and 1, where 1 refers to a high divergence from MSA. In addition to nuanced dialect identification at the country level, similarly to NADI 2023, NADI 2024 offers a machine translation (MT) track between four Arabic dialects (i.e., Egyptian, Emariti, Jordanian, and Palestinian) and MSA. This is an open track subtask where we allow participants to develop datasets under particular conditions and use them to develop systems. Namely, we allow participants to create datasets mapping dialectal Arabic into MSA that can be exploited to train their MT models.
NADI 2024 will be hosted by the Second Arabic Natural Language Processing Conference (ArabicNLP 2024). We invite participation in either of the three subtasks, we hope that teams will submit systems to multiple subtasks. By offering three subtasks, we hope to receive systems that exploit diverse machine learning approaches and architectures. This could include multi-task learning systems, distant supervision as well as sequence-to-sequence architectures in a single model such as the text-to-text Transformers (e.g., mT5, AraT5). Many other approaches could also be possible and we look forward to creative approaches to the subtasks.
SHARED TASK
This NADI 2024 shared task comprises three subtasks: multi-label country-level dialect identification (Subtask 1), level of dialectness estimation (Subtask 2), and machine translation from four Arabic dialects to MSA (Subtask 3).
Subtask 1 - Multi-label country-level Dialect Identification (MLDID) (Closed Track): Multi-label country-level dialect identification (MLDID) covering at least 10 dialects including Egyptian, Saudi Arabian, Algerian, Syrian, Palestinian, and Lebanese, depending on the availability of annotators. We will provide a development set (a targeted total of 100 samples) and a test set (a targeted total of 1000 samples) for the subtask. Each sample will be annotated for the set of dialects out of the 10 in which it is valid. Participants will be provided with NADI 2020 (Abdul-Mageed et al., 2020b), 2021 (Abdul-Mageed et al., 2021), and 2023 (Abdul-Mageed et al., 2023) training and development datasets to build and evaluate their multi-label classification systems. For evaluation, F1-scores will be computed for each country label and then macro-averaged into a single score.
Naturally occurring tweets will be used for the Dev and Test sets. For each of the covered dialects, native speakers of these dialects will validate if each tweet (sample) could be written by a speaker of this dialect or not.
Subtask 2 - ALDi Estimation (Open Track): Estimating the Arabic level of dialectness (ALDi) of Arabic sentences. Keleg et al. (2023b) define the Level of Dialectness as the extent by which a sentence diverges from the Standard Language. We use the same operationalization of modeling level of dialectness as a continuous score in the range [0, 1], where 0 means MSA, and 1 means high divergence from MSA. Participants are allowed to use public datasets such as ALDI-AOC (Keleg et al, 2023b ) which is a transformation of the AOC dataset (Zaidan and Callison-Burch, 2014), in addition to raw MSA and dialectal Arabic corpora. The participants should agree to report and share the external datasets they used to develop their systems. The samples of the development and test sets for subtasks 1 and 2 are the same. Root Mean Square Error (RMSE) will be used for evaluating the systems as follows:
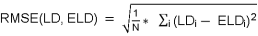 |
Where N is the number of samples, LD represents the target level of dialectness values of these samples, and ELD represents the estimated level of dialectness values. |
|
Sentence |
Algerian? |
Palestinian? |
… |
Tunisian? |
Egyptian? |
Expected ALDi |
|
يا ريتني ما تفرجت فالحلقة الأخيرة تاع #رحيم تأزمت بصراحة أبدع #ياسر_جلال فيه وليت مدمن عل مسلسل
|
✅ |
❌ |
… |
✅ |
❌ |
High (1) |
|
هو ورياح الشبابيك والابواب بتخبط كانه زلزال ربنا يستر
|
❌ |
✅ |
… |
❌ |
✅ |
Moderate (0.66) |
Subtask 3 - DA-MSA Machine Translation (Open Track): Sentence-level machine translation (MT) of four Arabic dialects into MSA. This subtask is an open track where we allow participants to use publicly available parallel datasets to use for training their MT systems. Participants are also allowed to create parallel datasets using manual and/or automated methods if they wish. For transparency and wider community benefits, we require researchers participating in the open track subtask to submit the datasets they create along with their Test set submissions.
We do not provide direct training data for this open track MT subtask. However, to facilitate the subtask, we provide one parallel dataset that can be used to train systems as well as a monolingual dataset that participants can manually translate and use for training. Details are below:
- MADAR parallel dataset: This dataset is available for acquisition directly from authors at: https://camel.abudhabi.nyu.edu/madar-parallel-corpus/. The dataset is a collection of parallel sentences covering the dialects of 25 cities from the Arab World, in addition to English, French, and MSA (Bouamor et al., 2018). Participants will be allowed to use only the Train split of MADAR parallel data for this subtask, and report on Dev and Test sets we provide. In other words, use of MADAR Dev and Test sets will not be allowed for this subtask.
- Monolingual datasets: As indicated in Subtask 1, we will make available monolingual datasets from previous NADI editions (NADI 2020, 2021, and 2023).
Our Test set for the MT subtask will be covering four dialects: Egyptian, Emariti, Jordanian, and Palestinian. In total, Test set is 2,000 sentences (500 from each dialect). We also provide a Dev set that we will release to participants (n=400 sentences, 100 from each of the four dialects). Both our Dev and Test sets for Subtask 3 are new datasets that we manually prepare for the shared task. We keep the domain from which these Dev and Test sets unknown.
To summarize, for the open track (Subtask 3; MT), we only release Dev and Test data. For the training data, participants are free to select their own or develop new training datasets. Participants can manually translate Mono-DA and/or Mono-MSA for that purpose, but they can also choose to acquire and translate any other datasets into any of the four dialects listed. Participants should agree to share the full used training dataset they create with the community. We will collect these datasets during submission time and facilitate their distribution from direct download links. Clearly, one objective of this open track shared task is to encourage creation of new datasets for machine translation of Arabic dialects.
In this subtask (MT), we will rank the teams based on (i) each dialect independently but also will provide (ii) the average overall score on all the four dialects.
METRICS
The macro-averaged F1-score, Root Mean Square Error (RMSE) and BLEU score will be the official metrics for Subtask 1, Subtask 2 and Subtask 3, respectively.
Evaluation of the shared task will be hosted through CODALAB. Teams will be provided with CODALAB links for the three subtasks.
- Subtask 1 - Multi-label country-level Dialect Identification (MLDID) (Closed Track): CodaLab link
- Subtask 2 - ALDi Estimation (Open Track): CodaLab link
- Subtask 3 - DA-MSA Machine Translation (Open Track): CodaLab Link
FT CODE
We provide a finetuning examples on Google Colab: TBD
IMPORTANT DATES
- February 25, 2024: Shared task announcement.
- March 15, 2024: A sample of the development sets made available.
- April 5, 2024: Registration deadline + Full development sets made available.
- April 15, 2024: Registration deadline (Extended).
- April 26, 2024: Test set made available.
- May 3, 2024: Codalab Test system submission deadline.
- May 20, 2024: Shared task system paper submissions due. (Extended)
- June 17, 2024: Notification of acceptance.
- July 1, 2024: Camera-ready version.
- August 16, 2024: ArabicNLP 2024 conference in Thailand.
CONTACT
For any questions related to this task, please contact the organizers directly using the following email address: ubc.nadi2020@gmail.com or join the google group.
REFERENCES
@inproceedings{abdul-mageed-etal-2020-nadi,
title = "{NADI} 2020: The First Nuanced {A}rabic Dialect Identification Shared Task",
author = "Abdul-Mageed, Muhammad and
Zhang, Chiyu and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Fifth Arabic Natural Language Processing Workshop",
month = dec,
year = "2020",
address = "Barcelona, Spain (Online)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wanlp-1.9",
pages = "97--110",
}
@inproceedings{abdul-mageed-etal-2021-nadi,
title = "{NADI} 2021: The Second Nuanced {A}rabic Dialect Identification Shared Task",
author = "Abdul-Mageed, Muhammad and
Zhang, Chiyu and
Elmadany, AbdelRahim and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Virtual)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.wanlp-1.28",
pages = "244--259",
}
@inproceedings{abdul-mageed-etal-2022-nadi,
title = "{NADI} 2022: The Third Nuanced {A}rabic Dialect Identification Shared Task",
author = "Abdul-Mageed, Muhammad and
Zhang, Chiyu and
Elmadany, AbdelRahim and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the The Seventh Arabic Natural Language Processing Workshop (WANLP)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.wanlp-1.9",
pages = "85--97",
}
@inproceedings{abdul-mageed-etal-2023-nadi,
title = "{NADI} 2023: The Fourth Nuanced {A}rabic Dialect Identification Shared Task",
author = "Abdul-Mageed, Muhammad and
Elmadany, AbdelRahim and
Zhang, Chiyu and
Nagoudi, El Moatez Billah and
Bouamor, Houda and
Habash, Nizar",
editor = "Sawaf, Hassan and
El-Beltagy, Samhaa and
Zaghouani, Wajdi and
Magdy, Walid and
Abdelali, Ahmed and
Tomeh, Nadi and
Abu Farha, Ibrahim and
Habash, Nizar and
Khalifa, Salam and
Keleg, Amr and
Haddad, Hatem and
Zitouni, Imed and
Mrini, Khalil and
Almatham, Rawan",
booktitle = "Proceedings of ArabicNLP 2023",
month = dec,
year = "2023",
address = "Singapore (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.arabicnlp-1.62",
doi = "10.18653/v1/2023.arabicnlp-1.62",
pages = "600--613",
}
}
@inproceedings{abdul-mageed-etal-2018-tweet,
title = "You Tweet What You Speak: A City-Level Dataset of {A}rabic Dialects",
author = "Abdul-Mageed, Muhammad and
Alhuzali, Hassan and
Elaraby, Mohamed",
editor = "Calzolari, Nicoletta and
Choukri, Khalid and
Cieri, Christopher and
Declerck, Thierry and
Goggi, Sara and
Hasida, Koiti and
Isahara, Hitoshi and
Maegaard, Bente and
Mariani, Joseph and
Mazo, H{\'e}l{\`e}ne and
Moreno, Asuncion and
Odijk, Jan and
Piperidis, Stelios and
Tokunaga, Takenobu",
booktitle = "Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018)",
month = may,
year = "2018",
address = "Miyazaki, Japan",
publisher = "European Language Resources Association (ELRA)",
url = "https://aclanthology.org/L18-1577",
}
@inproceedings{abdul-mageed-etal-2020-toward,
title = "Toward Micro-Dialect Identification in Diaglossic and Code-Switched Environments",
author = "Abdul-Mageed, Muhammad and
Zhang, Chiyu and
Elmadany, AbdelRahim and
Ungar, Lyle",
editor = "Webber, Bonnie and
Cohn, Trevor and
He, Yulan and
Liu, Yang",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-main.472",
doi = "10.18653/v1/2020.emnlp-main.472",
pages = "5855--5876",
abstract = "Although prediction of dialects is an important language processing task, with a wide range of applications, existing work is largely limited to coarse-grained varieties. Inspired by geolocation research, we propose the novel task of Micro-Dialect Identification (MDI) and introduce MARBERT, a new language model with striking abilities to predict a fine-grained variety (as small as that of a city) given a single, short message. For modeling, we offer a range of novel spatially and linguistically-motivated multi-task learning models. To showcase the utility of our models, we introduce a new, large-scale dataset of Arabic micro-varieties (low-resource) suited to our tasks. MARBERT predicts micro-dialects with 9.9{\%} F1, 76 better than a majority class baseline. Our new language model also establishes new state-of-the-art on several external tasks.",
}
@inproceedings{keleg-etal-2023-aldi,
title = "{ALD}i: Quantifying the {A}rabic Level of Dialectness of Text",
author = "Keleg, Amr and
Goldwater, Sharon and
Magdy, Walid",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.655",
doi = "10.18653/v1/2023.emnlp-main.655",
pages = "10597--10611",
abstract = "Transcribed speech and user-generated text in Arabic typically contain a mixture of Modern Standard Arabic (MSA), the standardized language taught in schools, and Dialectal Arabic (DA), used in daily communications. To handle this variation, previous work in Arabic NLP has focused on Dialect Identification (DI) on the sentence or the token level. However, DI treats the task as binary, whereas we argue that Arabic speakers perceive a spectrum of dialectness, which we operationalize at the sentence level as the Arabic Level of Dialectness (ALDi), a continuous linguistic variable. We introduce the AOC-ALDi dataset (derived from the AOC dataset), containing 127,835 sentences (17{\%} from news articles and 83{\%} from user comments on those articles) which are manually labeled with their level of dialectness. We provide a detailed analysis of AOC-ALDi and show that a model trained on it can effectively identify levels of dialectness on a range of other corpora (including dialects and genres not included in AOC-ALDi), providing a more nuanced picture than traditional DI systems. Through case studies, we illustrate how ALDi can reveal Arabic speakers{'} stylistic choices in different situations, a useful property for sociolinguistic analyses.",
}
@inproceedings{keleg-magdy-2023-arabic,
title = "{A}rabic Dialect Identification under Scrutiny: Limitations of Single-label Classification",
author = "Keleg, Amr and
Magdy, Walid",
editor = "Sawaf, Hassan and
El-Beltagy, Samhaa and
Zaghouani, Wajdi and
Magdy, Walid and
Abdelali, Ahmed and
Tomeh, Nadi and
Abu Farha, Ibrahim and
Habash, Nizar and
Khalifa, Salam and
Keleg, Amr and
Haddad, Hatem and
Zitouni, Imed and
Mrini, Khalil and
Almatham, Rawan",
booktitle = "Proceedings of ArabicNLP 2023",
month = dec,
year = "2023",
address = "Singapore (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.arabicnlp-1.31",
doi = "10.18653/v1/2023.arabicnlp-1.31",
pages = "385--398",
}
@article{zaidan-callison-burch-2014-arabic,
title = "{A}rabic Dialect Identification",
author = "Zaidan, Omar F. and
Callison-Burch, Chris",
journal = "Computational Linguistics",
volume = "40",
number = "1",
month = mar,
year = "2014",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/J14-1006",
doi = "10.1162/COLI_a_00169",
pages = "171--202",
}
@inproceedings{bouamor-etal-2018-madar,
title = "The {MADAR} {A}rabic Dialect Corpus and Lexicon",
author = "Bouamor, Houda and
Habash, Nizar and
Salameh, Mohammad and
Zaghouani, Wajdi and
Rambow, Owen and
Abdulrahim, Dana and
Obeid, Ossama and
Khalifa, Salam and
Eryani, Fadhl and
Erdmann, Alexander and
Oflazer, Kemal",
booktitle = "Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018)",
month = may,
year = "2018",
address = "Miyazaki, Japan",
publisher = "European Language Resources Association (ELRA)",
url = "https://aclanthology.org/L18-1535",
}